2016.08.22
データサイエンティスト養成講座 第6回受講レポート
7月20日、第6回目のデータサイエンティスト養成講座が開催されました。前回より「Jリーグ観客動員数を予測せよ!」のコンペが始まり、実際に行われたJリーグ公式戦2014年シーズン後半戦全試合の観客動員数を予測するモデルを作っています。
各チーム、試行錯誤をしながらモデルを作ってみたようです。受講者のみなさんが実践されている工夫の一部をご紹介します!
・数値のカテゴリ化(土曜の昼、土曜の夜などに分けて)をしてみた。
・変数を整形し、天気、湿度、月、曜日、時間などをダミー変数化した。
・天気と湿度で不快指数を作る。
・スタジアムの名前や住所がそれぞれ微妙に違うので整理した。
・選手名鑑を作ってみた。トレインデータとテストデータでそれぞれリストを作ってテストをしてみたが、選手の数が異なってしまった。トレインデータとテストデータをマージした上で重複しない選手リストを作らなければいけないと思った。
・(過去のデータなら使ってもいいとのことなので)外部データとして年ごとのMVPに選ばれた人でカラムを作ってみようと考えている。※未来のデータを使うのはNGです(念のため)
・その日が休日かどうかだけでなく、翌日が休日かも考慮した。
・祝日をデータから抜き出すのが辛かったので「NIPPON」パッケージを利用した。

ユニークなアイデアがたくさん出ましたね!一筋縄ではいかない今回のコンペに、みなさん苦戦しているようです。
続いて、中野講師(FEG)より同じく「Jリーグ観客動員数を予測せよ!」で、どのように情報を整理してモデルを良くしていくかについて講義がありました。前半の各チームからの発表では様々なアイデアが出ましたが、ここでは外的要因よりもチーム毎の動員力を探るためのチーム情報をモデルに取り入れ、また、試合会場がホームかアウェイかによっても影響が大きいのではと仮説を立て、それぞれに分けてモデルを扱うアプローチが紹介されました。
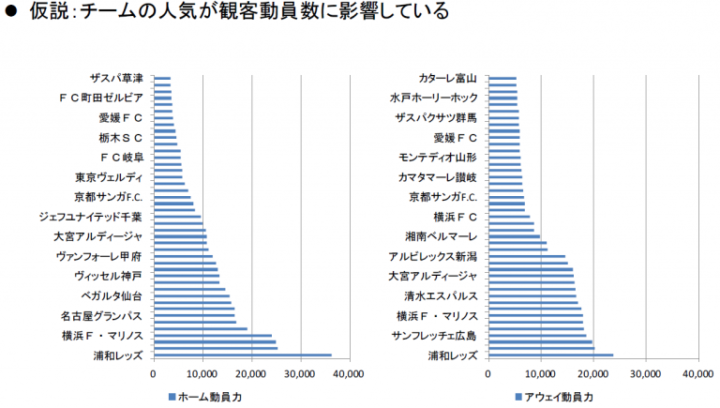
グラフを見てみると、どちらも浦和レッズの人気は高いのは一目瞭然ですが、チームによる格差(傾斜)はホームグラウンドで試合が行われた時の方が大きく、チームの人気の高さはホームでの観客動員数への影響が強いと考えられます。ということはチームの情報はモデルに取り入れた方がいい、ということですね!
ホームとアウェイのチーム情報をモデルに入れるためのアプローチは2つあります。
1.チームをダミー変数化する
2.チームの平均的な動員数をモデル変数に採用する
J1-J2のフラグ、ホームチームのダミー変数、アウェイチームのダミー変数をつかって重回帰してみると、バリデーションのスコアは3800くらいになりました。
さらに、チームの順位…特に優勝争いをしているとか、J1-J2入れ替えの降格争いをしているといった試合は集客数に影響がでそうですよね。観客動員数と順位をプロットしたグラフがこちらです。
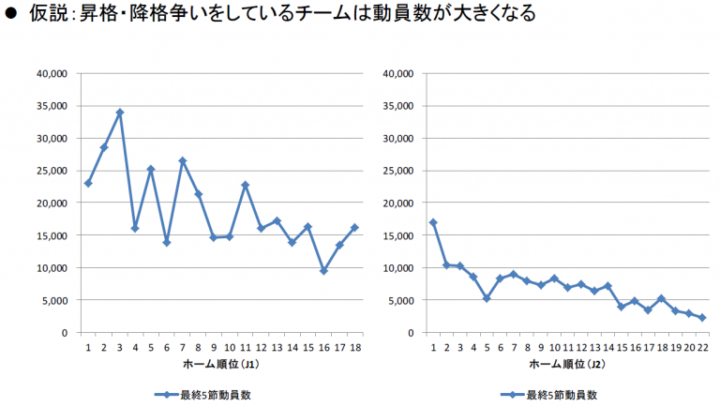
J1のグラフでは12~13位あたりに浦和レッズが位置しているため、そこだけ動員数が跳ね上がっています。一方J2のグラフでは綺麗に右肩下がりになっており、順位と集客力に関係がありそうに見えます。ただし、単純な順位と集客力の関係ではなく、強いチームは人気があるということが集客に作用しているかもしれないので、その相関は取り除いた上で効果を検証する必要があります。先ほどのモデルにホーム側とアウェイ側の順位という変数を付け加えて重回帰を行うとバリデーションスコアが3700くらいになりました。
また、中林塾長からは観客動員数の人数を見るのではなく、スタジアムのキャパシティに対して何%埋まったかを指標にしてみるのもいい、というアドバイスもありました。他にもスコアを良くするためのコツはたくさんあります。みなさんも是非、ひらめいたアイデアを試してみて下さい。次回もお楽しみに!
第7回の受講レポートはこちら
- カテゴリ
-
-
DS関連NEWS
-
インタビュー
-
スキルアップ
-
コラム
-
教えて!DS
-
- アーカイブ
-
-
2025年
-
2024年
-
2023年
-
2022年
-
2021年
-
2020年
-
2019年
-
2018年
-
2017年
-
2016年
-
- 記事アクセスランキング
-



- タグ


