2016.07.05
2016 第1回データサイエンティスト協会 勉強会
2016年6月15日、データサイエンティスト協会 勉強会2016 第1回『データサイエンスの全体像』と題して株式会社金融エンジニアリング・グループ(以下、FEG)の創業者であり、チーフ・データサイエンティストの中林 三平氏による講演が内田洋行 東京ユビキタス協創広場 CANVAS(八丁堀)で開催されました。
講演では、「情報」や「分析」という言葉がデータサイエンス分野ではどのように理解されるべきか、データサイエンスの手法の体系と概要、そして人材育成として、KDD CUPで2位という好成績を叩き出した世界トップレベルのデータサイエンティストたちを有するFEG社のデータサイエンティスト育成方法が紹介されました。今回は、その講演内容をレポートします!
【登壇者】
株式会社金融エンジニアリング・グループ
創業者 チーフ・データサイエンティスト
中林 三平氏
1948年生まれ。1971年、自由学園男子最高学部(理科)卒業、日本ユニバック総合研究所入社。1973年、野村総合研究所入社。1981年、社費留学にてUniversity of Pennsylvania 公共政策学修士、1982年、同大博士課程修了(意思決定理論)。AIコンサルティング室長として第五世代コンピュータプロジェクトなどに関わる。1989年、同社を退社し、株式会社金融エンジニアリング・グループを設立。代表取締役。2014年、同社代表取締役を退任。現在は、同社チーフ・データサイエンティストとして後進の指導にあたる。データサイエンティスト協会理事。
「情報」、「分析」、「データサイエンティスト」
「データサイエンス」という言葉が使われ始めたのはいつからなのでしょうか。1960年代、ハードウェアに関する研究が「コンピュータサイエンス」と言われていたのに対し、コンピュータが扱う情報つまりデータの分析に関わる研究分野を表す言葉として「データサイエンス」が誕生しました。しかし、当時に比べて現在では「データサイエンス」の意味合いが変わってきており、今ではより広範囲のスキル、仕事を指すようになってきたそうです。また、Wikipediaでのデータサイエンティストの定義と、データサイエンティスト協会が2014年に発表したスキルセットが紹介され、それぞれ異なる点があるものの、「情報を分析する」という点においては定義が一致しているとのことでした。さらに、分析の様々なレベルとして、Descriptive Analytics ・ Predictive Analytics ・ Prescriptive Analytics(第1回データサイエンティスト養成講座参照)が説明されました。

株式会社金融エンジニアリング・グループ 中林 三平氏
「分析」に関わる技術の紹介
データ分析は統計の勉強から始めるというイメージがありませんか?実はそうでもないのです。実際の社会現象においてはデータ量は大規模で偏りがあるので、伝統的な統計学が成立しないことが多々あります。「データマイニング」という考え方は分析するデータの規模拡大と共に発展してきました。
データ分析には教師あり学習(推定すべき指標が定義されており、分析対象とするデータに含まれている)と教師なし学習(上記以外)があります。ほとんどの場合は「教師あり」の分析なのですが、「教師なし」学習の手法を適用する場合として「クラスタリング」(属性・行動プロファイルが似た者を寄せ集めていくつかのグループにまとめる)や「異常値検出」(普通とは異なる行動を示す人を発見する)があります。異常値検出は機密文書漏洩の防止などに使われます。一方で、「教師あり」学習は、被説明変数(ターゲット)がカテゴリー(クラス)なのか連続量なのかで分けられます。
さらに、「教師あり」学習のアルゴリズムとして、Decision Treeという手法、Decision Treeの課題であるOver Fitting(過剰適合)を避けるためのCross Validation、それを拡大したRandom Forest、そしてその発展型のXgboostという高速・高精度・高安定性を持つモデルが紹介されました。しかし、Xgboostを使っても分析者によって得られる結果が異なります。変数を加工したり、組み合わせたりして「特徴量」を生み出す作業、Feature Engineeringが必要なのです。Feature Engineeringには、こうすればいいという正解がないので、良いモデル・特徴量を作るには感性・創造力が問われます。あえて強調するならば、データサイエンティストとは、「アーティスト」でもある(!)とのことでした。
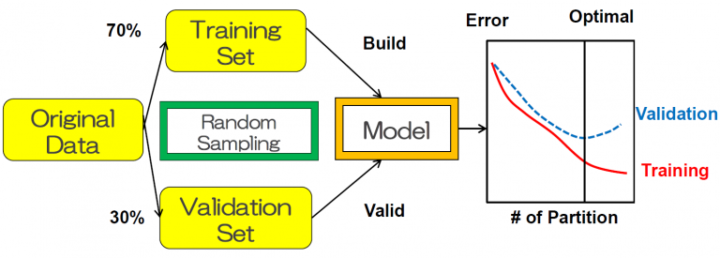
Over Fitting を避けるための工夫
データサイエンティストの育成方法
データサイエンティストになるためのバックグラウンドに「理系」「文系」は問われません。修士卒・学部卒も大きな差はありません。FEG社で行われている新卒データ分析技術者の教育の中でも、特に力を入れているのは、データ分析コンペへの参加です。2015年のKDDCUPでFEG社のチームが2位に輝いたのは記憶に新しいですね。コンペの参加は、きれいなデータではなく、現実的なノイズがあったり汚いデータが用いられるため、分析者のスキルアップにはベストなトレーニングのようです。
データサイエンスの分野は技術の進歩がとても早いため、気を抜くとあっという間に「時代遅れ」となってしまいます。中林氏は最後に、熟練の分析者であっても勉強を続けることが大事である、と強調されていました。実際に、中林氏も今でも現役データサイエンティストとして分析コンペに参加されています。常に新しい情報をキャッチアップし、日々怠ることなく自身のスキルを磨いていくことがトップデータサイエンティストになるための必須条件なのだと、痛切に感じた講演でした。

データサイエンティスト協会では「データサイエンティストのスキルチェックテスト」を公開しています。自分がデータサイエンティストとして結構イケてるのか、まだまだ勉強が足りないのか、レベルを確認することができます。腕試しにチェックしてみてくださいね!
※本勉強会の資料はこちら
- カテゴリ
-
-
DS関連NEWS
-
インタビュー
-
スキルアップ
-
コラム
-
教えて!DS
-
- アーカイブ
-
-
2025年
-
2024年
-
2023年
-
2022年
-
2021年
-
2020年
-
2019年
-
2018年
-
2017年
-
2016年
-
- 記事アクセスランキング
-



- タグ


