2016.08.19
データサイエンティスト養成講座 第5回受講レポート
第5回目のデータサイエンティスト養成講座が7月6日に開催されました。今回から後半戦に入り、DeepAnalyticsのコンテストにおいても各チームの特色が出てくるようになってきました。
本養成講座では、これまで「銀行の顧客ターゲティング」の練習問題に取り組んでおり、今回も前回と同様に各チームがモデルを作る際に工夫した点の発表からスタートしました。
ここではその一部をご紹介します!なお、本講座では各チームに(ちょっとマニアックな)魚の名前が付いています(笑)
・サクラダイチーム
ツリー系とglm系をアンサンブルしました。ツリーはランダムフォレストを使って、glmはロジスティック回帰をやりました。新しいモデルを作るのではなく、重みを調整しました。ロジスティック回帰の重みを非常に小さくしてやってみると良い結果が得られました。
・スナメリチーム(魚ではありませんが…)
まずは本講座で習ったモデルを全変数を使って試してみました。アンサンブルでは平均法とモデル再構築(ロジスティック回帰のみ)を行ってみましたが、結果が良かった平均法を採用。
・クマノミチーム
チーム3名で決定木、ロジスティック回帰、ランダムフォレストを行い、3つのモデルを平均してみました。結果は3つの平均よりもランダムフォレスト単体のスコアの方が高く、平均する時の重み付けが課題。
・マンボウチーム
初めてのコンペ参加で、力技で頑張りました(笑)。ランダムフォレストとGBM、xgboostを使い、4:3:3の割合でまるめると、良いスコアが出ました。しかしこの2日間くらいで他チームに抜かれてしまい、変数を変えたり、クロスバリデーションで精度を確認すればよかったと反省しています。
・ホウボウチーム
ランダムフォレスト、GBM、ロジスティック回帰を5:4:1と6:3:1の割合で混ぜ、それらを単純平均しました。また、データの分割など無限の組み合わせがあり時間がいくらあっても足りない中で、スプライン補間という手法を使ったところうまく精度が上がりました。
みなさん、試行錯誤をしながら講師陣が驚くほど精度を上げていっています。データサイエンスの世界では答えは一つではなく、着目点やアプローチの方法によって、それぞれ異なる結果が出てくるのですね!

各チームからの発表風景
さらに、データハンドリングについての解説がありました。今回より、本講座では新しいコンテスト「Jリーグ観客動員数を予測せよ!」(練習問題)に取り掛かります。今回の課題としてアップされているデータは4種類ありますので、分析のために、それを一つにしなければなりません。実務においてモデルを作成するときには、多くの場合、様々なソースのデータを結合して分析する必要がありますので、データの結合の手法については、いろいろなやり方を覚えておくのがよいです。今回はRでのデータ結合について簡単に解説をします。
・左結合:IDを結合の基準とすると、左側データにあるIDと同じ右側データのIDを紐づけるデータ結合(右側データにIDがない変数は欠損)
・右結合:右側データに存在するIDと同じ左側データのIDを紐づけるデータ結合(左側データにIDがない変数は欠損)
・内部結合:データAとB共通するIDのみ出力する。そして、左側データと右側データの両方に存在するIDを紐づけるデータ結合
・完全外部結合:単純に全部足して全部のデータを出力する、左側データまたは右側データに存在するIDを紐づけるデータ結合(左側もしくは右側データにIDのない変数は欠損)。
・アンチ結合:左側データに存在し, 右側データに存在しないIDを抽出するデータ結合
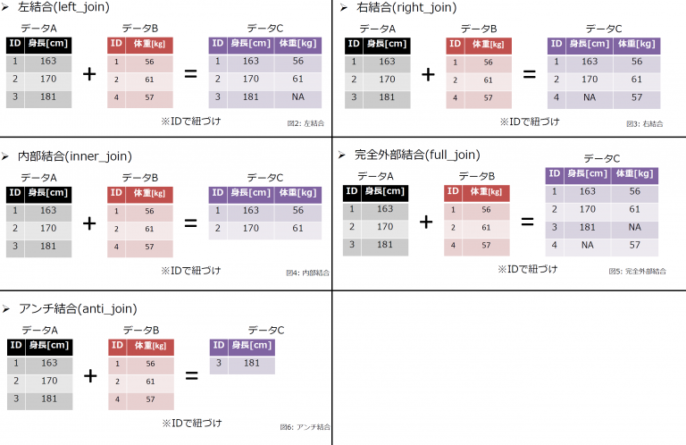
実際にデータを結合してみると、スタジアムの名前やサッカー選手の名前について表記が微妙に違ったり、半角と全角の違いがあったりで、本来であれば同じデータであるはずですが、テストデータにはあるが、トレインデータには存在しないということがありえます。こういうところをきれいにする、データクリーニングの作業が、分析の過程では一番時間がかかり、かつ、重要になります。結局はデータを良くみることが必要なのですが、これについては「うまい方法」はありませんので、みなさん頑張ってコツをつかんで下さい。
次回からいよいよ本格的にJリーグのデータ分析が始まります。お楽しみに!
第6回の受講レポートはこちら
- カテゴリ
-
-
DS関連NEWS
-
インタビュー
-
スキルアップ
-
コラム
-
教えて!DS
-
- アーカイブ
-
-
2026年
-
2025年
-
2024年
-
2023年
-
2022年
-
2021年
-
2020年
-
2019年
-
2018年
-
2017年
-
2016年
-
- 記事アクセスランキング
-





- タグ


